深入浅出了解llm模型微调
- IT
- 2025-09-28
- 442热度
- 0评论
0.引言
但是,在面对一些特殊性的应用场景时,这类通用型大预言模型往往表现的不尽如人意。 比如在法律,医疗领域内,需要模型具有强大的专业知识和技能,才能在这些垂直领域内 提供更精准、更有价值的服务。这类通用型大语言模型需要针对特定领域进行微调,以适 应特殊应用场景的需求。
微调(Fine-tuning)是一种让预训练模型适应特定任务或领域的技术。通过在特定领域的数据集上进行额外训练,模型可以获得该领域的专业知识和语言特点,从而提高在特定应用场景下的性能表现。
微调的主要优势包括:
- 提高特定领域的准确性和专业性
- 减少模型在专业领域的错误和幻觉
- 使模型更好地理解和生成领域特定的术语和表达
- 提升用户体验和满意度
对于法律、医疗等专业领域,微调后的模型能够更准确地理解专业术语、法规条文或医学知识,从而提供更可靠的服务和建议。这种针对性的优化使大语言模型能够在各个垂直领域发挥更大的价值。
并且微调是基于已有的大预言模型二次训练得到的,不光可以继承基础模型的语言能力和已具备的知识,还可以强化模型在特定领域的专业表现。因此,微调成为了将大语言模型应用到特定场景的关键技术,为模型赋予了更强的针对性和实用价值。本文将深入探讨LLM模型微调的原理、方法和实践应用,帮助读者全面了解这一重要技术。
以下介绍一些前置知识,以便于读者可以更好的明白
首先,所有的llm模型都是通过训练得到的,何为训练? 简单来说就是教育模型学习知识,就像是老师教小孩子一样。
那么知识的形式是什么? 我们学习可以通过视频,课本,书籍等,而模型的学习是通过一个叫作数据集的东西,所以数据集其实就是我们人类的课本,是承载模型学习知识的载体。那么实际表现就是一条条特定格式的数据。
模型是如何学会这些知识的呢?
简单来说,模型是通过参数的变化调整来学习的。一旦模型的参数发生改变,就表明模型在进行学习,所以无论是train还是fine本质都是通过外界数据的输入让其内部的参数发生改变。
具体过程如下
输入数据 → 前向传播 → 计算损失 → 反向传播 → 更新参数
本文所有实践微调实验,都会基于qwen3 系列模型。
1.什么是微调(Fine-tuning)?
微调也分为多种微调, 主要包括:全参数微调(Full Parameter Fine-tuning)、参数高效微调(Parameter-EfficientFine-tuning,PEFT)以及 指令微调(Instruction Tuning)。全参数微调是最为直接的方法,但需要较大的计算资源;参数高效微调(如LoRA、P-Tuning等)则通过仅更新部分参数来降低资源消耗;而指令微调则专注于使模型能够更好地理解和执行人类指令。
本文主要介绍lora微调,受限于现有设备,以及训练的速度,只能如此。所有的微调的原理其实基本都差异不大,无非是使用的架构、微调策略、学习率的区别。个人认为,要依据具体的业务场景来选择微调的方法。
2. 如何进行微调呢?(qlora微调qwen3例)
2.1 微调方式
废话不多说,本文以实践为主,直接来实战吧
这里以qwen3 的微调为例,主要的过程原理如图1所示
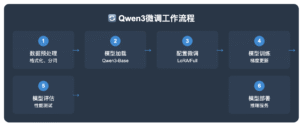
图1
采用lora微调,冻结一部分底层模型权重,来进行训练(微调),如图2
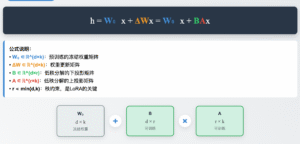
图2
r是lora微调的关键,r是LoRA中最关键的超参数,控制着低秩分解的秩大小,直接决定了模型的表达能力和效率平衡。
简单来说,r就代表了lora可以动的参数大小,r的值越大,代表微调的参数越多,反之越小,动的参数越小。以下是常见的r值对照表
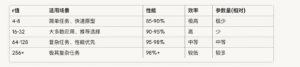
微调中最关键的数值就是r,一般需要小运行几次,来找到最佳的r值是多少。
对比传统的微调,lora微调在尽力不损失原有模型能力的情况下,大幅度减少计算量与参数量。


2.2 微调实验准备工作
a.实验服务器配置
本实验采用了一台ubuntu服务器,具体配置如下
cpu:i510400f
gpu: rtx3080 20g 、1050ti 4g
RAM: 32g ddr4 2666
ROM:ssd 1t
b.实验用到的基础模型以及数据集
模型: llm 模型 qwen3 1.7b q4量化版本
数据集:来自于huggingface :
https://huggingface.co/datasets/ystemsrx/Erotic_Literature_Collection?not-for-all-audiences=true
主要关于中文色情文学的,用于提升qwen3在色情写作方面的能力
c. 实验具体流程
1. 新建用于实验的conda环境
本次实验完全基于conda虚拟环境进行构建,新建任意名称的虚拟环境。
需要以下的资源
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 1_gnu
accelerate 1.10.1 pypi_0 pypi
aiohappyeyeballs 2.6.1 pypi_0 pypi
aiohttp 3.12.15 pypi_0 pypi
aiosignal 1.4.0 pypi_0 pypi
annotated-types 0.7.0 pypi_0 pypi
async-timeout 5.0.1 pypi_0 pypi
attrs 25.3.0 pypi_0 pypi
bitsandbytes 0.47.0 pypi_0 pypi
bzip2 1.0.8 h5eee18b_6
ca-certificates 2025.9.9 h06a4308_0
certifi 2025.8.3 pypi_0 pypi
charset-normalizer 3.4.3 pypi_0 pypi
click 8.2.1 pypi_0 pypi
datasets 4.0.0 pypi_0 pypi
dill 0.3.8 pypi_0 pypi
expat 2.7.1 h6a678d5_0
filelock 3.13.1 pypi_0 pypi
frozenlist 1.7.0 pypi_0 pypi
fsspec 2024.6.1 pypi_0 pypi
gitdb 4.0.12 pypi_0 pypi
gitpython 3.1.45 pypi_0 pypi
hf-xet 1.1.9 pypi_0 pypi
huggingface-hub 0.34.4 pypi_0 pypi
idna 3.10 pypi_0 pypi
jinja2 3.1.4 pypi_0 pypi
ld_impl_linux-64 2.40 h12ee557_0
libffi 3.4.4 h6a678d5_1
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h5eee18b_0
libxcb 1.17.0 h9b100fa_0
libzlib 1.3.1 hb25bd0a_0
markupsafe 2.1.5 pypi_0 pypi
mpmath 1.3.0 pypi_0 pypi
multidict 6.6.4 pypi_0 pypi
multiprocess 0.70.16 pypi_0 pypi
ncurses 6.5 h7934f7d_0
networkx 3.3 pypi_0 pypi
numpy 2.1.2 pypi_0 pypi
nvidia-cublas-cu11 11.11.3.6 pypi_0 pypi
nvidia-cuda-cupti-cu11 11.8.87 pypi_0 pypi
nvidia-cuda-nvrtc-cu11 11.8.89 pypi_0 pypi
nvidia-cuda-runtime-cu11 11.8.89 pypi_0 pypi
nvidia-cudnn-cu11 9.1.0.70 pypi_0 pypi
nvidia-cufft-cu11 10.9.0.58 pypi_0 pypi
nvidia-curand-cu11 10.3.0.86 pypi_0 pypi
nvidia-cusolver-cu11 11.4.1.48 pypi_0 pypi
nvidia-cusparse-cu11 11.7.5.86 pypi_0 pypi
nvidia-nccl-cu11 2.21.5 pypi_0 pypi
nvidia-nvtx-cu11 11.8.86 pypi_0 pypi
openssl 3.0.17 h5eee18b_0
packaging 25.0 pypi_0 pypi
pandas 2.3.2 pypi_0 pypi
peft 0.17.1 pypi_0 pypi
pillow 11.0.0 pypi_0 pypi
pip 25.2 pyhc872135_0
platformdirs 4.4.0 pypi_0 pypi
propcache 0.3.2 pypi_0 pypi
protobuf 6.32.1 pypi_0 pypi
psutil 7.0.0 pypi_0 pypi
pthread-stubs 0.3 h0ce48e5_1
pyarrow 21.0.0 pypi_0 pypi
pydantic 2.11.7 pypi_0 pypi
pydantic-core 2.33.2 pypi_0 pypi
python 3.10.18 h1a3bd86_0
python-dateutil 2.9.0.post0 pypi_0 pypi
pytz 2025.2 pypi_0 pypi
pyyaml 6.0.2 pypi_0 pypi
readline 8.3 hc2a1206_0
regex 2025.9.1 pypi_0 pypi
requests 2.32.5 pypi_0 pypi
safetensors 0.6.2 pypi_0 pypi
sentry-sdk 2.37.1 pypi_0 pypi
setuptools 78.1.1 py310h06a4308_0
six 1.17.0 pypi_0 pypi
smmap 5.0.2 pypi_0 pypi
sqlite 3.50.2 hb25bd0a_1
sympy 1.13.3 pypi_0 pypi
tiktoken 0.11.0 pypi_0 pypi
tk 8.6.15 h54e0aa7_0
tokenizers 0.22.0 pypi_0 pypi
torch 2.7.1+cu118 pypi_0 pypi
torchaudio 2.7.1+cu118 pypi_0 pypi
torchvision 0.22.1+cu118 pypi_0 pypi
tqdm 4.67.1 pypi_0 pypi
transformers 4.56.1 pypi_0 pypi
triton 3.3.1 pypi_0 pypi
trl 0.23.0 pypi_0 pypi
typing-extensions 4.12.2 pypi_0 pypi
typing-inspection 0.4.1 pypi_0 pypi
tzdata 2025.2 pypi_0 pypi
urllib3 2.5.0 pypi_0 pypi
wandb 0.21.4 pypi_0 pypi
wheel 0.45.1 py310h06a4308_0
xorg-libx11 1.8.12 h9b100fa_1
xorg-libxau 1.0.12 h9b100fa_0
xorg-libxdmcp 1.1.5 h9b100fa_0
xorg-xorgproto 2024.1 h5eee18b_1
xxhash 3.5.0 pypi_0 pypi
xz 5.6.4 h5eee18b_1
yarl 1.20.1 pypi_0 pypi
zlib 1.3.1 hb25bd0a_0
这里提供一个包安装脚本
#!/bin/bash
# Qwen3微调环境安装脚本
# 基于现有qwen3_wiki环境生成
echo "🚀 开始创建Qwen3微调环境..."
# 检查conda是否安装
if ! command -v conda &> /dev/null; then
echo "❌ Conda未找到,请先安装Anaconda或Miniconda"
exit 1
fi
# 设置环境名称
ENV_NAME="qwen3_fine_tuning"
# 检查环境是否已存在
if conda env list | grep -q "$ENV_NAME"; then
echo "⚠️ 环境 $ENV_NAME 已存在,是否删除并重新创建? (y/n)"
read -r response
if [[ "$response" =~ ^([yY][eE][sS]|[yY])$ ]]; then
conda env remove -n "$ENV_NAME" -y
echo "🗑️ 已删除旧环境"
else
echo "❌ 取消安装"
exit 1
fi
fi
# 创建基础conda环境(Python 3.10.18)
echo "📦 创建基础conda环境..."
conda create -n "$ENV_NAME" python=3.10.18 -y
# 激活环境
echo "🔧 激活环境..."
source "$(conda info --base)/etc/profile.d/conda.sh"
conda activate "$ENV_NAME"
# 验证环境激活
if [[ "$CONDA_DEFAULT_ENV" != "$ENV_NAME" ]]; then
echo "❌ 环境激活失败"
exit 1
fi
echo "✅ 环境已激活: $CONDA_DEFAULT_ENV"
# 升级pip
echo "📈 升级pip..."
pip install --upgrade pip
# 安装PyTorch及CUDA相关包
echo "🔥 安装PyTorch (CUDA 11.8)..."
pip install torch==2.7.1+cu118 torchaudio==2.7.1+cu118 torchvision==0.22.1+cu118 --index-url https://download.pytorch.org/whl/cu118
# 安装核心AI/ML包
echo "🤖 安装核心AI/ML包..."
pip install transformers==4.56.1
pip install datasets==4.0.0
pip install accelerate==1.10.1
pip install peft==0.17.1
pip install trl==0.23.0
# 安装量化和优化包
echo "⚡ 安装量化和优化包..."
pip install bitsandbytes==0.47.0
pip install triton==3.3.1
# 安装数据处理包
echo "📊 安装数据处理包..."
pip install numpy==2.1.2
pip install pandas==2.3.2
pip install pyarrow==21.0.0
# 安装工具包
echo "🛠️ 安装工具包..."
pip install tqdm==4.67.1
pip install click==8.2.1
pip install pyyaml==6.0.2
pip install regex==2025.9.1
pip install tiktoken==0.11.0
pip install tokenizers==0.22.0
pip install safetensors==0.6.2
# 安装网络和API包
echo "🌐 安装网络和API包..."
pip install requests==2.32.5
pip install aiohttp==3.12.15
pip install huggingface-hub==0.34.4
# 安装监控和日志包
echo "📈 安装监控包..."
pip install wandb==0.21.4
pip install sentry-sdk==2.37.1
pip install psutil==7.0.0
# 安装其他依赖包
echo "📚 安装其他依赖包..."
pip install pillow==11.0.0
pip install jinja2==3.1.4
pip install markupsafe==2.1.5
pip install packaging==25.0
pip install filelock==3.13.1
pip install fsspec==2024.6.1
pip install platformdirs==4.4.0
pip install sympy==1.13.3
pip install mpmath==1.3.0
pip install networkx==3.3
pip install typing-extensions==4.12.2
# 安装验证包
echo "📝 安装验证相关包..."
pip install pydantic==2.11.7
pip install pydantic-core==2.33.2
pip install annotated-types==0.7.0
# 安装时间处理包
echo "⏰ 安装时间处理包..."
pip install python-dateutil==2.9.0.post0
pip install pytz==2025.2
pip install tzdata==2025.2
# 安装其他工具包
echo "🔧 安装其他工具包..."
pip install six==1.17.0
pip install urllib3==2.5.0
pip install certifi==2025.8.3
pip install charset-normalizer==3.4.3
pip install idna==3.10
pip install attrs==25.3.0
pip install multiprocess==0.70.16
pip install dill==0.3.8
pip install xxhash==3.5.0
pip install protobuf==6.32.1
# 安装Git相关包
echo "📂 安装Git工具..."
pip install gitpython==3.1.45
pip install gitdb==4.0.12
pip install smmap==5.0.2
# 安装异步相关包
echo "🔄 安装异步处理包..."
pip install aiohappyeyeballs==2.6.1
pip install aiosignal==1.4.0
pip install async-timeout==5.0.1
pip install frozenlist==1.7.0
pip install multidict==6.6.4
pip install propcache==0.3.2
pip install yarl==1.20.1
# 安装HuggingFace相关包
echo "🤗 安装HuggingFace生态包..."
pip install hf-xet==1.1.9
pip install typing-inspection==0.4.1
# 验证安装
echo "✅ 验证安装..."
# 创建验证脚本
cat > verify_installation.py << 'EOF'
#!/usr/bin/env python3
"""验证Qwen3微调环境安装"""
import sys
import importlib
def check_package(package_name, display_name=None):
"""检查包是否正确安装"""
if display_name is None:
display_name = package_name
try:
module = importlib.import_module(package_name)
version = getattr(module, '__version__', 'unknown')
print(f"✅ {display_name:20} {version}")
return True
except ImportError as e:
print(f"❌ {display_name:20} 未安装 - {e}")
return False
def main():
print("🔍 验证Qwen3微调环境安装")
print("=" * 50)
# 核心包检查
core_packages = [
('torch', 'PyTorch'),
('transformers', 'Transformers'),
('datasets', 'Datasets'),
('accelerate', 'Accelerate'),
('peft', 'PEFT'),
('trl', 'TRL'),
('bitsandbytes', 'BitsAndBytes'),
]
print("\n🔥 核心AI/ML包:")
core_success = 0
for pkg, name in core_packages:
if check_package(pkg, name):
core_success += 1
# 工具包检查
tool_packages = [
('numpy', 'NumPy'),
('pandas', 'Pandas'),
('tqdm', 'TQDM'),
('wandb', 'Weights & Biases'),
('tiktoken', 'TikToken'),
]
print("\n🛠️ 工具包:")
tool_success = 0
for pkg, name in tool_packages:
if check_package(pkg, name):
tool_success += 1
# CUDA检查
print("\n🚀 CUDA检查:")
try:
import torch
print(f"✅ CUDA可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"✅ CUDA版本: {torch.version.cuda}")
print(f"✅ GPU数量: {torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
print(f"✅ GPU {i}: {torch.cuda.get_device_name(i)}")
else:
print("⚠️ CUDA不可用,将使用CPU")
except Exception as e:
print(f"❌ CUDA检查失败: {e}")
# 总结
print("\n📊 安装总结:")
print(f"核心包: {core_success}/{len(core_packages)}")
print(f"工具包: {tool_success}/{len(tool_packages)}")
if core_success == len(core_packages) and tool_success == len(tool_packages):
print("🎉 环境安装完成!可以开始Qwen3微调了")
return True
else:
print("⚠️ 部分包安装失败,请检查错误信息")
return False
if __name__ == "__main__":
main()
EOF
# 运行验证
python verify_installation.py
# 创建快速测试脚本
cat > quick_test.py << 'EOF'
#!/usr/bin/env python3
"""快速功能测试"""
print("🧪 快速功能测试")
print("=" * 30)
try:
# 测试PyTorch
import torch
print(f"✅ PyTorch: {torch.__version__}")
# 测试Transformers
from transformers import AutoTokenizer
print("✅ Transformers导入成功")
# 测试PEFT
from peft import LoraConfig
print("✅ PEFT LoRA配置导入成功")
# 测试基本张量操作
x = torch.randn(2, 3)
y = torch.matmul(x, x.T)
print("✅ PyTorch张量操作正常")
# 测试CUDA(如果可用)
if torch.cuda.is_available():
x_cuda = x.cuda()
print("✅ CUDA张量操作正常")
print("\n🎉 所有测试通过!环境就绪")
except Exception as e:
print(f"❌ 测试失败: {e}")
EOF
python quick_test.py
# 创建环境使用说明
cat > README.md << 'EOF'
# Qwen3微调环境使用说明
## 环境激活
```bash
conda activate qwen3_fine_tuning
核心包版本
- Python: 3.10.18
- PyTorch: 2.7.1+cu118
- Transformers: 4.56.1
- PEFT: 0.17.1
- TRL: 0.23.0
- BitsAndBytes: 0.47.0
快速开始
1. 基础LoRA微调
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig, get_peft_model
# 加载模型
model_name = "Qwen/Qwen3-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# LoRA配置
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
lora_dropout=0.1,
)
# 应用LoRA
model = get_peft_model(model, lora_config)
2. 使用TRL进行SFT
from trl import SFTTrainer
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=5e-4,
num_train_epochs=3,
logging_steps=10,
save_steps=500,
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
args=training_args,
train_dataset=your_dataset,
)
trainer.train()
监控和日志
- 使用Weights & Biases:
wandb login - 查看GPU使用:
nvidia-smi - 监控训练进度: 查看TensorBoard日志
故障排除
- CUDA内存不足: 减少batch_size或使用gradient_checkpointing
- 包冲突: 重新创建环境
- 权限问题: 检查文件夹写入权限
EOF
输出安装完成信息
echo ""
echo "🎉 Qwen3微调环境安装完成!"
echo ""
echo "📝 使用说明:"
echo "1. 激活环境: conda activate $ENV_NAME"
echo "2. 查看README: cat README.md"
echo "3. 验证安装: python verify_installation.py"
echo "4. 快速测试: python quick_test.py"
echo ""
echo "🚀 现在可以开始Qwen3微调了!"
请按照上述的名称与版本来构建环境,注意,如果采用不同的版本可能会出现兼容性的问题。
### 2.构建训练数据集
采用如下脚本进行构建
```python
import torch
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer
import json
import os
"""
使用ystemsrx/Erotic_Literature_Collection
构建本地数据集用于微调Qwen
采用保守的处理方式:
- 保守的上下文使用:避免信息过载
- 统一的格式:所有样本都遵循相同的格式
- 高质量过滤:确保每个样本都有效
- 适度长度:控制token数量,适合快速训练
"""
def load_and_preprocess_data():
"""加载并预处理ystemsrx/Erotic_Literature_Collection数据集 - 保守版"""
print("正在加载Erotic_Literature_Collection数据集...")
# 从huggingface 上加载数据集
dataset = load_dataset("ystemsrx/Erotic_Literature_Collection")
print(dataset)
print(dataset.keys())
print(f"训练集样本数: {len(dataset['train'])}")
# 加载tokenizer
model_name = "Qwen/Qwen-1_8B" # 保持与你的原始代码一致
print(f"加载tokenizer: {model_name}")
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 修复token问题
if tokenizer.eos_token is None:
tokenizer.eos_token = "<|endoftext|>"
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
print(f"EOS token: {tokenizer.eos_token}")
# 手动处理数据,避免map函数的问题
max_length = 512 # 保守的长度设置
def _process_examples(dataset_split):
processed_data = []
print(f"开始处理数据...")
for i, example in enumerate(dataset_split):
if i % 1000 == 0:
print(f"已处理: {i}/{len(dataset_split)}")
try:
# 提取文本内容
text = example.get('text', '') or ""
# 基本验证
if not text or len(text.strip()) < 50: # 跳过太短的文本
continue
# 清理文本
text = clean_text(text)
if not text:
continue
# 构建训练格式 - 使用简单的续写格式
prompt = "请继续这个故事:\n"
# 截取适当长度的文本作为prompt
if len(text) > 1000:
# 取前面一部分作为prompt,后面作为completion
split_point = min(300, len(text) // 3)
story_prompt = text[:split_point].rsplit('.', 1)[0] + '.' # 在句子边界截断
story_completion = text[len(story_prompt):].strip()
if len(story_completion) < 100: # 确保completion有足够内容
continue
full_prompt = prompt + story_prompt + "\n\n"
full_text = full_prompt + story_completion + tokenizer.eos_token
else:
# 短文本直接作为completion
full_text = prompt + text + tokenizer.eos_token
# 编码检查长度
input_ids = tokenizer.encode(full_text)
if len(input_ids) > max_length:
# 尝试截断
truncated_text = tokenizer.decode(input_ids[:max_length-1]) + tokenizer.eos_token
input_ids = tokenizer.encode(truncated_text)
# 添加到处理后的数据
processed_data.append({
"text": full_text,
"input_ids": input_ids,
"token_count": len(input_ids)
})
except Exception as e:
print(f"样本 {i} 处理失败: {e}")
continue
print(f"处理完成! 有效样本数: {len(processed_data)}")
return processed_data
def clean_text(text):
"""清理文本内容"""
if not isinstance(text, str):
return ""
# 基础清理
text = text.strip()
# 移除过多的换行符和空白
lines = [line.strip() for line in text.split('\n') if line.strip()]
text = '\n'.join(lines)
# 移除特殊字符序列
import re
text = re.sub(r'\s+', ' ', text) # 多个空格合并为一个
text = re.sub(r'\n{3,}', '\n\n', text) # 多个换行合并
# 长度检查
if len(text) < 50 or len(text) > 5000: # 跳过太短或太长的文本
return ""
return text.strip()
# 处理数据
processed_data = _process_examples(dataset['train'])
# 创建新的Dataset
processed_dataset = Dataset.from_list(processed_data)
return {"train": processed_dataset}, tokenizer
def save_processed_data(dataset, tokenizer, output_dir="./processed_erotic_literature"):
"""保存处理后的数据"""
os.makedirs(output_dir, exist_ok=True)
print(f"保存数据到 {output_dir}...")
# 保存数据集
dataset['train'].save_to_disk(f"{output_dir}/train_data")
# 保存tokenizer
tokenizer.save_pretrained(f"{output_dir}/tokenizer")
# 保存数据集信息
train_data = dataset['train']
lengths = [item['token_count'] for item in train_data]
info = {
"total_samples": len(train_data),
"tokenizer": tokenizer.name_or_path,
"max_length": 512,
"avg_length": sum(lengths) / len(lengths),
"min_length": min(lengths),
"max_length_actual": max(lengths),
"format": "story_continuation"
}
with open(f"{output_dir}/dataset_info.json", "w", encoding="utf-8") as f:
json.dump(info, f, indent=2, ensure_ascii=False)
print("数据保存完成!")
return info
def load_processed_dataset(dataset_path="./processed_erotic_literature"):
"""加载已处理的数据集"""
from datasets import load_from_disk
print(f"从 {dataset_path} 加载数据集...")
train_dataset = load_from_disk(f"{dataset_path}/train_data")
tokenizer = AutoTokenizer.from_pretrained(f"{dataset_path}/tokenizer", trust_remote_code=True)
with open(f"{dataset_path}/dataset_info.json", "r", encoding="utf-8") as f:
info = json.load(f)
print("数据集加载完成!")
print(f"数据集信息: {info}")
return train_dataset, tokenizer, info
if __name__ == "__main__":
try:
# 处理数据
dataset, tokenizer = load_and_preprocess_data()
# 保存数据
print("保存预处理数据...")
info = save_processed_data(dataset, tokenizer)
print("数据预处理完成!")
print(f"训练样本数: {info['total_samples']}")
print("文件保存位置:")
print(" - 数据集: ./processed_erotic_literature/train_data")
print(" - Tokenizer: ./processed_erotic_literature/tokenizer")
# 显示统计信息
print(f"序列长度统计:")
print(f" - 平均长度: {info['avg_length']:.1f}")
print(f" - 最大长度: {info['max_length_actual']}")
print(f" - 最小长度: {info['min_length']}")
# 显示样本
print("\n样本预览:")
sample = dataset['train'][0]
print(f"Token数: {sample['token_count']}")
print(f"内容预览: {sample['text'][:200]}...")
# 数据集划分建议
total_samples = len(dataset['train'])
train_size = int(total_samples * 0.9)
eval_size = total_samples - train_size
print(f"\n建议数据划分:")
print(f" - 训练集: {train_size} 样本")
print(f" - 验证集: {eval_size} 样本")
except Exception as e:
print(f"处理失败: {e}")
import traceback
traceback.print_exc()
ok ,代码有些难懂对吗?别急,让我来讲解下
首先要从huggingface 上下载数据集,需要用到dataset这个包,然后即可在python代码中引入数据
print("正在加载Erotic_Literature_Collection数据集...")
# 从huggingface 上加载数据集
dataset = load_dataset("ystemsrx/Erotic_Literature_Collection")
print(dataset)
print(dataset.keys())
print(f"训练集样本数: {len(dataset['train'])}")
这个dataset 是一个字典,可以工具规定的key来获取数据,至于具体的数据结构会写在网页中
例如本次所用到的数据集数据结构就如下图:

当本地没有数据的时候,会去huggingface的官方下载,并且存储在本地。
加载好了数据,我们还需要让qwen3 能看懂这些数据,因为现有数据集都是自然语言的,qwen3 模型并不能理解,模型的眼中只能理解特定的编码,所以就需要将自然语言进行转译,而tokenizer的作用就是这个,充当一个翻译的角色。每个不同的模型在训练的初期就已经定义好了自己的tokenizer,我这里只需要下载并且引用即可。具体操作如下,需要transformers库中的from_pretrained来进行加载
# 加载tokenizer
model_name = "Qwen/Qwen-1_8B"
print(f"加载tokenizer: {model_name}")
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
加载完毕了,这里需要注意下,由于qwen3 公开的tokenizer 并没有没有预配置标准的EOS和PAD token,但是实际上qwen 使用了 "<|endoftext|>" 作为结束标记,以及确实没有PAD token ,这在批次训练的时候很致命,所以需要修改下:
# 修复token问题
if tokenizer.eos_token is None:
tokenizer.eos_token = "<|endoftext|>"
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
加上eos,指定为<|endoftext|>,然后加上eos_token,这样即可处理多种长度的文本了。
解决了以上问题,我们现在可以来构建我们所需要的真正的数据集了,前面说了,我们的原始数据是一篇篇文章对吧,但是这显然无法直接进行训练,我们想要通过微调增强模型在色情文学中的续写能力,于是这次我们的策略如下:
• 从原始文本中截出一部分作为 prompt(context),剩下部分作为 “completion”(模型要生成的目标)。
• 模型训练时,以 prompt 为输入,以 completion 为真实目标,用交叉熵损失训练模型预测 completion 中的 token。
注意这个过程中我没有进行人工标注标签,而是 从文本自身拆出输入 vs 输出对,模型自己学“续写”语言的任务。
所以本次的训练数据集,不能完全算是无监督的数据集,也不能算是传统意义上的有监督类的训练,介于二者之间吧。
一下是实际的代码:
max_length = 512 # 保守的长度设置
def _process_examples(dataset_split):
processed_data = []
print(f"开始处理数据...")
for i, example in enumerate(dataset_split):
if i % 1000 == 0:
print(f"已处理: {i}/{len(dataset_split)}")
try:
# 提取文本内容
text = example.get('text', '') or ""
# 基本验证
if not text or len(text.strip()) < 50: # 跳过太短的文本
continue
# 清理文本
text = clean_text(text)
if not text:
continue
# 构建训练格式 - 使用简单的续写格式
prompt = "请继续这个故事:\n"
# 截取适当长度的文本作为prompt
if len(text) > 1000:
# 取前面一部分作为prompt,后面作为completion
split_point = min(300, len(text) // 3)
story_prompt = text[:split_point].rsplit('.', 1)[0] + '.' # 在句子边界截断
story_completion = text[len(story_prompt):].strip()
if len(story_completion) < 100: # 确保completion有足够内容
continue
full_prompt = prompt + story_prompt + "\n\n"
full_text = full_prompt + story_completion + tokenizer.eos_token
else:
# 短文本直接作为completion
full_text = prompt + text + tokenizer.eos_token
# 编码检查长度
input_ids = tokenizer.encode(full_text)
if len(input_ids) > max_length:
# 尝试截断
truncated_text = tokenizer.decode(input_ids[:max_length-1]) + tokenizer.eos_token
input_ids = tokenizer.encode(truncated_text)
# 添加到处理后的数据
processed_data.append({
"text": full_text,
"input_ids": input_ids,
"token_count": len(input_ids)
})
except Exception as e:
print(f"样本 {i} 处理失败: {e}")
continue
print(f"处理完成! 有效样本数: {len(processed_data)}")
return processed_data
- 每次的 prompt前缀都一样,提示模型继续续写。
- 如果文本很长 (> 1000 字符),就划分为两部分:
- story_prompt:截取前面一部分(取 split_point,这个点是 min(300, len(text)//3),确保不要太少也不要太多),并尝试在一个句号 “.” 处分割,以保证不要中断在句子中间。
- story_completion:剩下的后部分作为模型要“生成”的目标。
- 如果 story_completion 太短(<100字符),则跳过这个样本(认为不够生成意义)。
- full_prompt 是 prompt 前缀 + story_prompt + 两个换行(分割清晰)。
- full_text 则是 prompt + prompt 部分 + completion 部分 + tokenizer.eos_token(加上结束符号,以标记序列结束)。
- 如果文本不长,就把整个 text 作为 completion(prompt 后直接接),同样在末尾加 eos_token。
- 把 full_text 用 tokenizer.encode 编码成 token id 列表 input_ids。
- 如果编码后长度超过允许的 max_length,就尝试截断:先切掉到 max_length-1,然后再在末尾加上 eos_token,然后重新 encode。
- 这样保证 input_ids 的长度 ≤ max_length。
- 最终把这个样本加入结果中,带上文本、编码和长度。